You have built a following for your coverage of election polling, but you’re not a pollster?
That’s right, I’m a neuroscientist. My current research focuses on learning and plasticity—the brain’s ability to have lasting change.
At Bell Labs as a postdoc in 1998, I developed an interest in synaptic learning rules. Synapses are the connections in the brain that allow neurons to pass a signal to one another. Memory and learning are thought to be partly stored in those connections and affected by how strong they are and how frequently they change. At Princeton, I studied how the exact timing of synaptic activity led to plasticity.
Today, I’m primarily focused on the cerebellum, which is found at the back of the brain. We’ve long known that this region is important to coordination, movement, and balance. But I’m interested in the possibility that it may do more. My lab now has some pretty good evidence that the cerebellum may act as a developmental teacher to help organize the brain in early life.
So that’s my day job. Then, as a hobby on the side, I also run the Princeton Election Consortium website.
How did you first become interested in politics?
Back in 1995, when I was just starting out, I did a fellowship in Congress, where I worked for Senator Ted Kennedy on research policy and the use of technology in K–12 schools. That was my first real exposure to government, and it’s held my fascination ever since. Even when I returned to academia full-time, I followed politics closely.
During the 2000 contest between George W. Bush and Al Gore, I started paying attention to state polls. Within the data, I noticed early on that the election seemed to come down to Florida. And indeed, history revealed that to be true. The fact that one state could be so pivotal to an entire election fascinated me.
So I wrote a MATLAB script to model how one could use state polls to track the presidential race between Bush and John Kerry in 2004. I published the results online, demonstrating that the race came down to Florida, Ohio, and Pennsylvania. My post went viral with social scientists, political scientists, and stock traders. It even made the front page of the Wall Street Journal. That was my first exposure to a wider audience, but it was all still a novelty—just a nerdy little story about a scientist crunching numbers.
How did you transition to doing it more regularly?
By 2008, Obama’s first election, I had set up a regular website, the Princeton Election Consortium. My original motivation was to cut through the chaos of news coverage and try to come up with a snapshot of where the race was. It was a hobby, purely an informational resource. I never have made any money from it.
But I wasn’t the only one doing this. Dozens of hobbyists were getting into the mix. And of course everyone knows Nate Silver, whose website FiveThirtyEight went viral that year. With so much data from public pollsters available, the time was right for data-heavy coverage of national politics.
By 2012, poll aggregation really went mainstream and even appeared to contradict the reporting on the race between Obama and Mitt Romney.
Right. Nate went over to the New York Times, where his blog accounted for about 20 percent of visitors in the run-up to that year’s election. A number of other news outlets, such as the Huffington Post and CNN, began to include more tracking analysis.
But while the journalists and data wonks might have been in the same paper, they weren’t necessarily on the same page. There’s a tendency in news to provide equivalency—to make a race between two contenders seem close and down to the wire.
Many news outlets portrayed Mitt Romney as neck and neck with Obama right up to the end. But the poll aggregates—mine, Nate’s, and others’—showed Obama with a clear lead. The question became, who was right? When the results came in—the pre-election polling medians were correct in every single state. Pollsters, as a community, did very well at surveying state opinion. It was a triumph for what we now call data journalism.
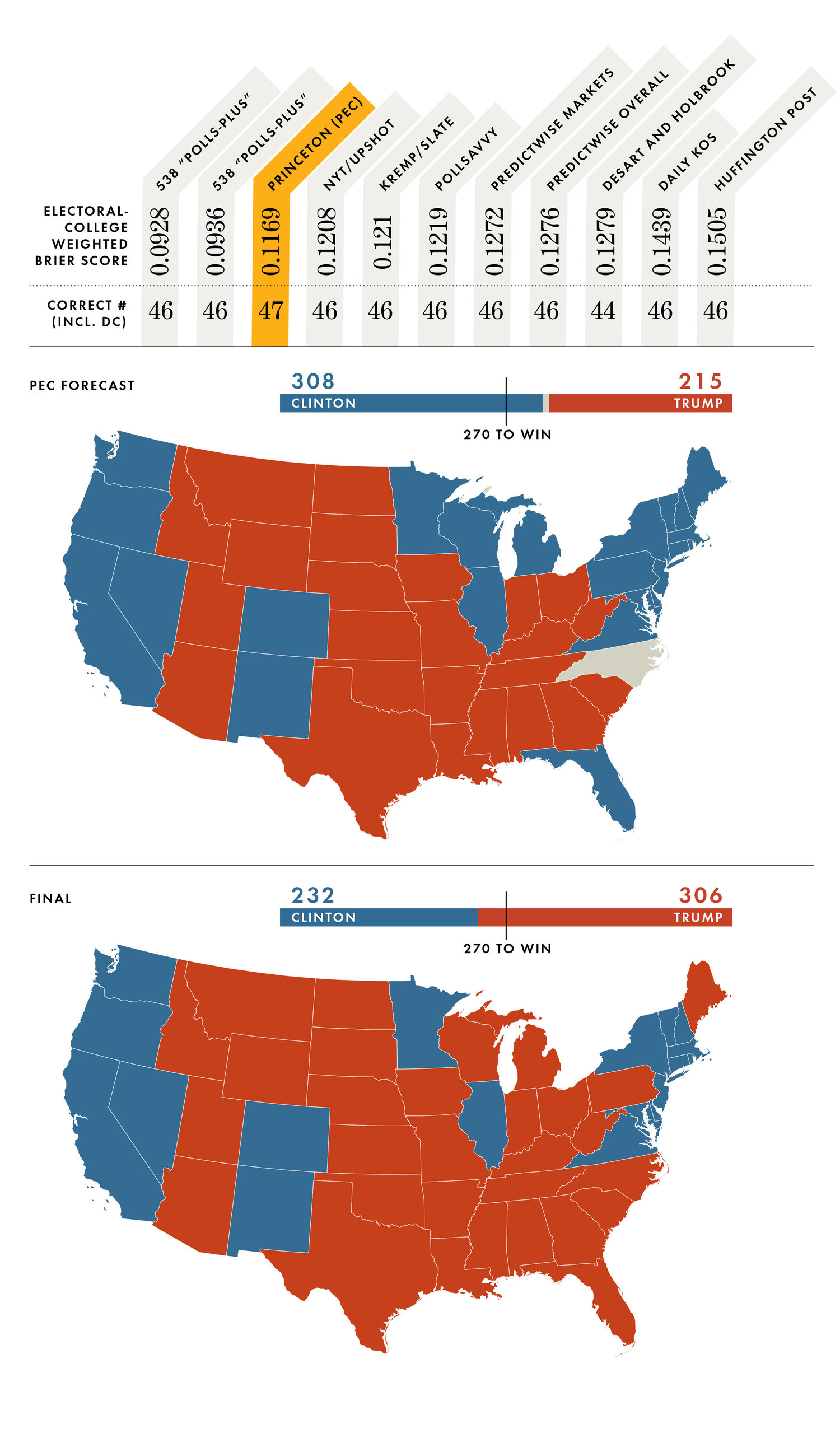
That’s not quite what happened last year, though. Most poll analysts predicted a Clinton win. You were particularly confident, saying that her victory was 99 percent certain.
Yeah, the story was much different this time, of course. We were all off—both journalists and poll aggregators. I have to admit that I was particularly off. Painfully so. I think I can talk about it now with some distance.
First, we should remember that despite all of the recent success, polling aggregation and analysis at this scale is young, it has only been around since about 2004. And until this election, the predictions had done well. Even in 2016, there are points where we did well. During the primaries, I used state polls to point out that Mr. Trump was the strong favorite to win the nomination. So we had enjoyed a good track record. But poll aggregation has its limits. It gets rid of only the random sampling noise. If there’s a larger systematic error, then results can go off track. And it turns out, there was such an error lurking in the polls.
For most of the race, Hillary Clinton’s effective lead in state polls was between two and six percentage points. Then you have to take into account an overall systematic error, which historically is around one or two percentage points. Clinton held a lead for most of the season ahead of that margin. She consistently looked positioned for a narrow win at the minimum.
But this election, the overall error in state polls was four points. That’s large, and meant something was systemically off. The entire polling industry—public, campaign-associated, aggregators—ended up with data that missed the results by a very large margin.
In my postmortem analysis, it looks to me like undecided Republican voters—those who couldn’t figure out whether they were really going to support such a radical candidate—showed up as undecided in the polls. But on election day, they stayed loyal to their party.
Indeed the polling error was concentrated in Republican-leaning states. In states that Donald Trump won, the error was an average of six percentage points. In Democratic states where Clinton won, the error was 0.2 percentage points.
We based our predictions on past behavior of all voters, Democrats, Republicans, and undecided voters. But this was an unusual year, where many of the undecideds were in fact Republican. And in the end, they came home en masse.
We were hamstrung by inadequate data—and so we were wrong. In my case, I compounded the error by underestimating the range of uncertainty.